En Bref
- Project Spend Caps arrive dans AI Studio pour plafonner les dépenses par projet, avec un léger délai d’application d’environ 10 minutes.
- Les Usage Tiers sont repensés : seuils abaissés, passages automatiques et plafond mensuel par compte de facturation.
- Des tableaux de bord détaillent l’usage et la tarification : requêtes et tokens par minute, ventilation quotidienne des coûts, erreurs et configuration.
- De nouveaux outils innovants d’optimisation arrivent : implicit caching, budgets de raisonnement, modèles Gemini 2.5/3.1 plus efficients.
- Un rattrapage attendu après le bug de facturation de 2025, avec des garde-fous comparables aux pratiques d’OpenAI et d’Anthropic.
Le lancement par Google de nouveaux garde-fous pour l’API Gemini réorganise la maîtrise des coûts pour les équipes IA. Les plafonds de dépenses par projet dans AI Studio, la refonte des Usage Tiers et des tableaux de bord dédiés changent la donne. Ce virage arrive après un incident de tarification survenu en 2025. La compétition avec OpenAI et Anthropic se joue désormais autant sur l’optimisation budgétaire que sur la performance des modèles.
Pour les responsables cloud et les équipes de développement, l’enjeu est clair : piloter une gestion des dépenses fine, sans sacrifier la qualité. Les nouveaux contrôles se combinent à des techniques comme l’implicit caching et aux derniers modèles Gemini 2.5/3.1. Ils apportent une réponse pragmatique : sécuriser le run, absorber des pics, et aligner la technologie avec les objectifs métiers. Les prochains mois devraient voir naître des pratiques plus matures de tarification IA.
API Gemini : contrôles budgétaires et paliers repensés pour une maîtrise des coûts fiable
Project Spend Caps dans AI Studio : un plafond par projet, simple et actionnable
La nouveauté la plus attendue se nomme Project Spend Caps. Elle permet de définir un plafond mensuel par projet directement dans AI Studio. L’activation se fait depuis l’onglet Spend. Le paramètre reste en vigueur jusqu’à modification. Cette logique évite les envolées imprévues, surtout lors de tests intensifs.
Un détail compte toutefois : un délai d’environ 10 minutes s’applique après tout changement. Des dépassements durant cette fenêtre restent dus. Concrètement, il faut anticiper les ajustements avant une campagne ou une montée de charge. Un rappel automatique côté process interne sécurise ce point.
Usage Tiers : seuils abaissés, montée automatique, plafonds par compte
Les Usage Tiers évoluent fortement. Les seuils d’accès aux paliers supérieurs sont abaissés. Le passage s’effectue de façon automatique et immédiate dès que les critères sont atteints. Cette souplesse évite des goulots en pleine production. Elle empêche aussi des requêtes bloquées au pire moment.
Chaque palier définit désormais un plafond mensuel par compte de facturation. L’enveloppe s’ajuste donc au niveau d’usage. Les équipes financières y gagnent en visibilité. Les développeurs bénéficient d’un cadre lisible pour monter en charge sans surprise.
Étude de cas : une marketplace qui encadre ses coûts en moins d’une semaine
Prenons l’exemple de CaddieX, une marketplace européenne. Son équipe data a migré le chat produit vers Gemini. Les coûts ont grimpé pendant une campagne événementielle. Les Product Owners ont alors fixé un Spend Cap à 12 000 € sur le projet front. Dans la foulée, un palier supérieur s’est déclenché automatiquement, mais le plafond a contenu l’impact.
Le résultat est net : le trafic a tenu. Les coûts mensuels sont restés conformes au budget. L’équipe a ensuite ouvert un projet dédié aux tests. Elle a fixé un plafond beaucoup plus bas pour ce périmètre. Les expérimentations ont continué, sans risque pour la production.
Retour sur 2025 : un incident qui a accéléré le virage
À l’été 2025, un bug a mal catégorisé des tokens internes. Des appels purement textuels ont été facturés au tarif image. Des développeurs ont vu des montants à quatre chiffres. Google a reconnu l’erreur et annoncé des remboursements. Mais l’absence de plafonds avait amplifié la casse.
Face à une concurrence déjà mieux outillée, le rattrapage devenait impératif. D’ailleurs, les dynamiques du marché ont basculé, comme le retrace cet éclairage : l’équilibre entre Gemini et ChatGPT a évolué. Le déploiement actuel aligne désormais Gemini sur les standards attendus.
Ces ajustements cadrent la dépense et redonnent confiance. Ils posent surtout une base saine pour les prochaines vagues d’adoption. Les projets IA peuvent grandir dans un cadre budgétaire solide.

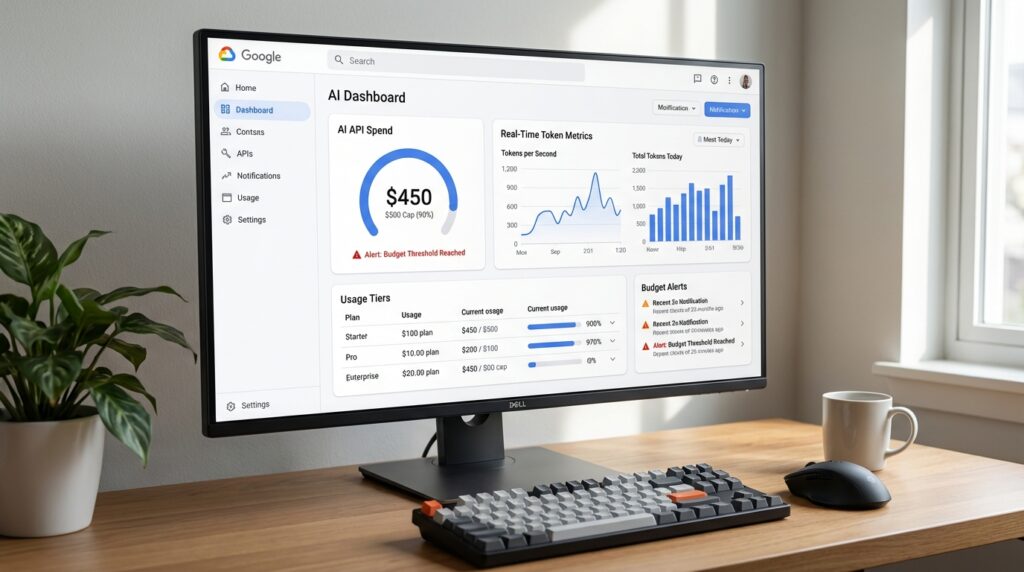
Tableaux de bord, métriques et alertes : piloter la gestion des dépenses en temps réel
Des vues qui collent aux besoins opérationnels
Les nouveaux tableaux de bord d’AI Studio suivent les rate limits avec le détail des requêtes et tokens par minute. Une ventilation quotidienne affiche les coûts par projet et par modèle. Des métriques d’erreurs aident à corriger vite. Enfin, la configuration de la facturation se gère au même endroit. Le pilotage devient continu.
Cette centralisation évite les angles morts. Les Data Engineers visualisent la latence et la saturation. Les Product Managers lisent le coût par fonctionnalité. Les FinOps suivent l’évolution contre le budget. Chacun dispose d’un même référentiel.
Relier AI Studio au Cost Explorer Google Cloud
Pour une vue consolidée, beaucoup relient ces métriques à l’Explorateur de coûts Google Cloud. On observe alors l’impact multi-projets. Cela sert à arbitrer entre environnement de test et de production. Cela sert aussi à valider les hypothèses d’optimisation.
Les équipes avancées poussent l’analyse plus loin. Elles marient la consommation GPU, les quotas par région et le coût unitaire par token. Les décisions d’architecture s’en trouvent plus robustes. Le budget vit au rythme des usages réels.
Mise en pratique : définir des seuils et des alertes utiles
Un bon tableau de bord ne suffit pas sans alarmes. Un budget d’alerte fixé à 70 % du plafond prévient tôt. Un deuxième seuil à 90 % enclenche une action : désactiver une fonctionnalité non critique. La logique s’inspire du circuit breaker côté SRE. Elle protège l’expérience tout en maîtrisant la dépense.
Les équipes produits peuvent aussi afficher un message discret. Elles informent d’une dégradation temporaire. Le choix reste honnête, et le coût ne dérape pas. L’utilisateur voit un service stable, même en pic.
Check-list opérationnelle pour un déploiement fiable
- Créer un projet par domaine fonctionnel et activer Project Spend Caps.
- Configurer des alertes budgétaires à 70 % et 90 % du plafond.
- Suivre les Usage Tiers et planifier les montées de trafic.
- Ventiler le coût par modèle et désigner un modèle par défaut économe.
- Exporter les métriques vers l’Explorateur de coûts pour une lecture globale.
Cette rigueur réduit les surprises en fin de mois. Elle installe aussi un langage commun entre tech et finance. Les arbitrages gagnent en qualité, et vite.
Ce premier corpus de bonnes pratiques prépare la prochaine étape : tirer parti des outils d’optimisation avancés. C’est là que les gains s’accélèrent, sans rogner la performance.
Outils d’optimisation avancés : implicit caching, budgets de raisonnement et modèles plus efficients
Implicit caching : réduire la redondance, baisser la facture
Google introduit l’implicit caching dans l’API. Les requêtes répétitives réutilisent des fragments déjà calculés. Le coût baisse fortement sur des cas à prompts stables. Certaines équipes observent jusqu’à 75 % d’économies sur des flux récurrents. Les dashboards permettent d’en vérifier l’effet.
Sur un moteur de recherche interne, CaddieX a appliqué ce cache implicite. Les pages très consultées réutilisent des contextes partagés. La facture a chuté sur ces endpoints. Le budget libéré a financé des tests d’enrichissement par images.
Budgets de raisonnement sur Gemini 2.5 Flash et 2.5 Pro
Les budgets de réflexion étaient d’abord disponibles sur Gemini 2.5 Flash. Google les étend à Gemini 2.5 Pro. Les développeurs contrôlent le coût de chaînes de raisonnement. Ils choisissent quand autoriser un raisonnement long. Ils limitent cette option aux cas critiques. Le résultat : qualité ciblée, dépense contenue.
Sur un back-office logistique, ce budget a été fixé à faible par défaut. Un switch autorise un raisonnement plus profond si l’algorithme détecte une anomalie. Les faux positifs ont reculé. La dépense est restée sous contrôle.
Des modèles plus rapides et plus sobres
L’arrivée de Gemini 3.1 Pro renforce le cœur du raisonnement. La précision progresse. Le coût d’opération baisse par tâche résolue. Parallèlement, Gemini 2.5 Flash offre une exécution plus économe pour les cas temps réel. Le compromis vitesse/prix s’aligne avec les attentes produit.
Cette tendance se confirme dans l’écosystème. Les entreprises ajustent leurs choix de modèles selon le contexte. Pour suivre ces mouvements, cet aperçu est utile : panorama des outils IA en 2026. Il éclaire les combinaisons gagnantes du moment.
Exemples concrets : traduction, génération d’images et FAQ
Pour la traduction, les prompts récurrents profitent du cache. Les coûts chutent sur les glossaires stables. Les workflows gagnent en cohérence. Des avancées du côté de TranslateGemma montrent la voie pour des pipelines hybrides.
Pour la génération d’images, la vigilance s’impose. Les budgets de raisonnement ne s’appliquent pas à tout. Les coûts peuvent vite grimper. Un état des lieux des générateurs d’images en 2026 aide à cadrer l’usage. Les cas FAQ utilisent, eux, des modèles plus légers. Le cache y devient très rentable.
Au final, la boîte à outils couvre l’amont et l’aval. On supprime la redondance. On encadre la complexité. On choisit le bon modèle au bon moment.
Stratégies de tarification et architecture cloud pour un développement durable
Composer avec des politiques de coûts claires
Une stratégie saine commence par la tarification ciblée des parcours. Un prix plafond par fonctionnalité se décide. Les budgets se déclinent par environnement. Les paliers Usage Tiers guident la montée en charge. Les Product Owners valident ce cadre. Les FinOps le mesurent en continu.
Les environnements de test et de préproduction gardent des plafonds faibles. La production active des alarmes à 70 % et 90 %. Les features non critiques se désactivent au besoin. L’expérience reste correcte. Le budget ne déraille pas.
Patterns d’architecture pour contenir les coûts
Plusieurs patterns aident à tenir la ligne. Le routage de modèles dirige les requêtes simples vers Gemini 2.5 Flash. Les cas ardus vont vers des modèles plus puissants. Un cache partagé limite les redondances. Les prompts sont factorisés, versionnés et testés.
Les sources de contexte sont hiérarchisées. On charge d’abord des extraits légers. Les pièces longues ne s’ajoutent qu’en dernier recours. Le coût par requête baisse. La latence reste basse pour l’utilisateur.
Procédures et gouvernance du run
Des outils innovants n’ont d’effet qu’avec une bonne gouvernance. Un runbook décrit les seuils, les actions et les responsables. Les Spend Caps et les alertes y figurent. Les équipes SRE et produit l’utilisent lors des pics. Le pilotage devient fluide.
Voici une séquence type pour cadrer une mise en production Gemini :
- Définir un plafond par projet et des seuils d’alerte.
- Choisir un modèle par défaut économe et un modèle premium en fallback.
- Activer l’implicit caching sur les prompts stables.
- Mesurer le coût par fonctionnalité et par audience.
- Établir un plan de désactivation progressive des features non essentielles.
Cette discipline sert aussi la vitesse d’itération. Elle empêche de débattre du budget en urgence. L’énergie se concentre sur la valeur produit.
Écosystème concurrentiel et arbitrages
La pression du marché reste forte. OpenAI et Anthropic ont mis la barre haut sur les outils de gestion des dépenses. Google répond avec un ensemble cohérent. L’offensive plus large se lit ici : la contre-attaque face à OpenAI trace une trajectoire musclée.
Pour un CTO, l’arbitrage doit rester pragmatique. On compare la qualité par cas d’usage. On compare la facture totale. On choisit les briques qui livrent une valeur constante. Le reste suit naturellement.
Ces choix structurent la performance métier. Ils construisent une base durable pour l’IA de production. La stabilité budgétaire devient un avantage compétitif.
Gouvernance, conformité et scénarios de crise : éviter les dérives et réagir vite
Leçons de l’incident 2025 : garder un filet de sécurité
L’erreur de 2025 a rappelé une règle simple : aucun système n’est infaillible. Un plafond par projet sert de filet. Un plafond par compte de facturation renforce la protection. L’un sans l’autre reste incomplet. Ensemble, ils empêchent l’emballement.
Les équipes doivent aussi tracer les écarts de tarification. Un rapport hebdomadaire montre les anomalies. Le suivi devient un réflexe. Les arbitrages gagnent en précision. Les surprises diminuent fortement.
Playbook d’escalade : du signal faible à l’action forte
Un playbook clair accélère la réponse. À 70 % du plafond, l’équipe réduit la charge non critique. À 90 %, elle désactive un parcours coûteux. À 100 %, elle suspend les tests. Un message utilisateur informe sobrement. Ce schéma limite l’impact tout en préservant le cœur de l’offre.
Sur CaddieX, ce playbook a évité une dérive lors d’une opération flash. Une montée de trafic a poussé le coût à 85 %. L’équipe a coupé la recommandation visuelle. La disponibilité front n’a pas bougé. La facture s’est stabilisée.
Contrôles internes et conformité
La conformité n’est pas qu’un sujet juridique. Elle structure les responsabilités. Un responsable budget par domaine est désigné. Les droits d’édition sur Spend Caps sont restreints. Un audit mensuel passe en revue les changements. La traçabilité protège l’entreprise.
Les fournisseurs exigent souvent une visibilité détaillée. Les tableaux de bord de Google facilitent ces échanges. Les KPI sont clairs. Les décisions sont documentées. La relation reste saine.
Capacité d’apprentissage et boucle d’amélioration
Un système sain apprend de lui-même. Les métriques nourrissent des revues trimestrielles. Les prompts, les caches et les choix de modèles évoluent. Les outils innovants de Gemini forment un socle vivant. L’optimisation devient continue.
Pour anticiper les tendances, des veilles sectorielles aident. Les analyses sur l’adoption de l’IA et les mouvements d’acteurs offrent un cap. La stratégie reste connectée au terrain. Elle gagne en pertinence.
Au bout du compte, la maîtrise du risque et du coût renforce la confiance. Elle libère l’innovation sur des bases solides. Le pilotage garde la main sur la trajectoire.
On en dit Quoi ?
Ces ajouts placent enfin l’API Gemini au niveau attendu pour une IA de production. Project Spend Caps, Usage Tiers modernisés et dashboards réalignent la balance entre ambition et sobriété. Avec l’implicit caching et les budgets de raisonnement, la facture devient un levier stratégique, pas une inconnue. Le message est clair : la technologie doit servir l’usage et tenir le budget. Les acteurs qui adoptent ces pratiques dès maintenant sécuriseront des gains durables et un avantage concurrentiel réel.
Spécialiste en technologies et transformation numérique, fort d’une expérience polyvalente dans l’accompagnement d’entreprises vers l’innovation et la dématérialisation. Âgé de 26 ans, passionné par l’optimisation des processus et la gestion du changement.